Fixed Point Arithmetic in DSP
The purpose of this lecture is as follows.
To explain the difference between native and emulated floating point computation
To clarify the computational cost of emulated floating-point computation
To describe fixed-point data representation of signals
To describe arithmetic using fixed-point data representation
To discuss the effects of fixed-point arithmetic on DSP
To discuss the influence of coefficient quantization on FIR and IIR
To demonstrate the use of filter coefficient quantization in Matlab
Attention
Examples for this lecture are under https://github.com/wpi-ece4703-b24/fixedpointfilter
The cost of floating-point computation
Floating point representation is the default representation adopted in many scientific computations, as well as in the world of signal processing. Matlab, for example, will compute the filter coefficients by default in a double-precision (64-bit) precision.
On the other hand, compared to integer arithmetic, floating point arithmetic is complex. Since a floating point number is represented using a mantissa and an exponent, every arithmetic operation involving a floating point number implies operations on both the mantissa as well as the exponent. Furthermore, floating point numbers have to be aligned before every operation, and they have to be normalized after every operation. Floating point arithmetic has a high implementation cost, much larger than that of typical integer arithmetic.
In DSP processing applications, the increased complexity of floating point arithmetic will manifest itself in two areas.
If the target processor includes floating-point hardware (such as the Cortex-M4F that we’re using on our MSP432 experimentation board), then the use of floating point arithmetic - as opposed to integer arithmetic - will increase the power consumption of the processor. Further, given the same amount of operations between a floating-point precision and an integer precision program, then the floating-point precision program will require more energy.
If the target processor does not include floating-point hardware (for example, because it’s a smaller microcontroller), then floating-point operations will have to be emulated in software, which will lead to a significant performance hit.
Floating Point Emulation
Attention
The source code of this example is in the flp-emulated project of the repository for this lecture. Note that you have to change the compiler settings (from floating-point support to none) to experiment with emulated floating point calls. Furthermore, if you change the floating-point support model (from native to emulated), you also need to recompile the xlaudio_lib library.
It’s useful to elaborate on floating point emulation. Floating point emulation is used when a source application requires a floating point data type but there is no floating support at the hardware level (an approach called native floating point). In that case, the C compiler is responsible for inserting function calls to an emulation library that will implement the floating point operation using integer instructions (an approach called emulated floating point). Both strategies are controlled by a compiler flag (float_support in the case of the TI compiler). When emulated floating point is used, an emulation library will be needed as well. This library is typically part of the low-level support infrastructure of the compiler and does not require a specific modification in the settings of the linker. The emulation library contains compiled hand-optimized code and is not affected by the compiler optimization settings: an emulated operation such as a floating-point addition will always be implemented as efficiently as possible.
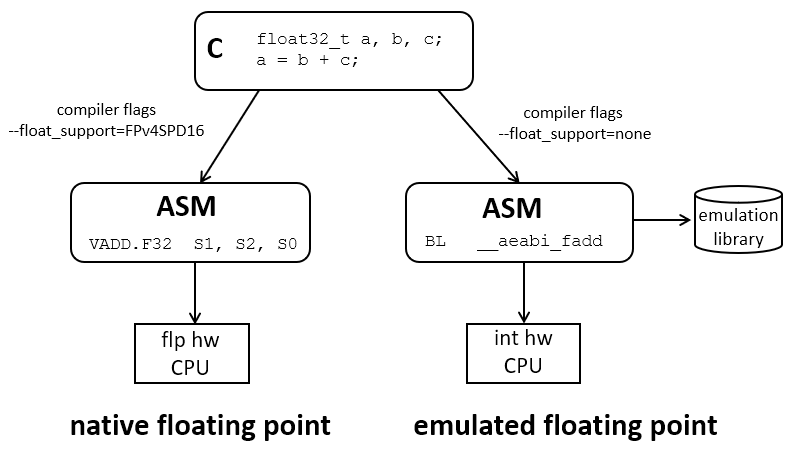
Nevertheless that still begs the question how efficient floating point emulation is on a microcontroller without floating point hardware. After all, if emulation would be an efficient strategy for DSP, then we could just focus on getting the best possible DSP algorithm in floating point and be done.
Consider the following 20-tap direct-form FIR in floating point precision.
#define FIRLEN 20
const float32_t coef_float[FIRLEN] = {
0.001588789281, 0.004897921812, 0.00443964405, -0.009905842133, -0.03936388716,
-0.06086875126, -0.03351534903, 0.0654496327, 0.204924494, 0.3078737259,
0.3078737259, 0.204924494, 0.0654496327, -0.03351534903, -0.06086875126,
-0.03936388716, -0.009905842133, 0.00443964405, 0.004897921812, 0.001588789281
};
float32_t taps_float[FIRLEN];
float32_t fir_float(float32_t x) {
taps_float[0] = x;
float32_t q = 0.0;
uint16_t i;
for (i = 0; i<FIRLEN; i++)
q += taps_float[i] * coef_float[i];
for (i = FIRLEN-1; i>0; i--)
taps_float[i] = taps_float[i-1];
return q;
}
We compile this function with floating point support, and inspect the assembly file at the output (select ‘Properties->Build->Compiler->Advanced->Assembler->Generate Listing’). The following snippet shows the assembly of the multiply-accumulate loop. The compiler optimization is off, which results in slightly inefficient code. Nevertheless, one can clearly see the use of floating point instructions such as VLDR.32, VMLA.32 and VSTR,32.
loop:
LDRH A4, [SP, #8]
LDR A1, taps_float
LDRH A3, [SP, #8]
LDR A2, coef_float
VLDR.32 S1, [SP, #4] ; q
ADD A1, A1, A4, LSL #2 ; address &taps_float[i]
VLDR.32 S0, [A1, #0]
ADD A2, A2, A3, LSL #2 ; address &coef_float[i]
VLDR.32 S2, [A2, #0]
VMLA.F32 S1, S2, S0 ; q = q + taps_float[i]*coef_float[i]
VSTR.32 S1, [SP, #4]
LDRH A1, [SP, #8] ; increment i
ADDS A1, A1, #1
STRH A1, [SP, #8]
LDRH A1, [SP, #8] ; test i
CMP A1, #20
BLT loop
Next, we compile the same function with emulated floating point support, and inspect the assembly code. The floating point instructions have been replaced with function calls starting with __aeabi_... which indicates they are functions that belong the the ARM Application Binary Interface (ABI) which includes the implementation for emulated floating point instructions. While the processing sequence if slightly different - eg. the 32-bit floating point numbers are read from memory before being passed on as arguments to the floating point emulated call - the overall number of instructions between native floating point, and emulated floating point, are similar. Thus, any difference in cycle count must come form the overhead of doing __aeabi_... calls as opposed to native floating point instructions.
loop:
LDRH A1, [SP, #8]
LDR A4, taps_float
LDRH A2, [SP, #8]
LDR A3, coef_float
LDR A1, [A4, +A1, LSL #2] ; taps_float[i]
LDR A2, [A3, +A2, LSL #2] ; coef_float[i]
BL __aeabi_fmul ; taps_float[i]*coef_float[i]
MOV A2, A1
LDR A1, [SP, #4]
BL __aeabi_fadd ; q = q + result
STR A1, [SP, #4]
LDRH A1, [SP, #8] ; increment i
ADDS A1, A1, #1
STRH A1, [SP, #8]
LDRH A1, [SP, #8] ; test i
CMP A1, #20
BLT loop
Using xlaudio_measurePerfSample() we now measure the cycle difference between these two cases. Without optimization, emulating the computations of a 20-tap FIR is about 2.27 times slower than the native case. However, on an optimized implementation, that factor increases to 8.17 times. The reason is that in both case, the emulation library (__aeabi_.. calls) is already optimized, and hence the used of the optimization flag has less impact on emulated floating point computation.
20-tap FIR |
No optimization |
Global (2) optimization |
Unit |
|---|---|---|---|
Native Flp |
1,339 |
2,80 |
cycles |
Emulated Flp |
3,042 |
2,287 |
cycles |
Ratio (emu/nat) |
2.27x |
8.17x |
Overall, this result paints a pretty dire picture for real-time DSP on microprocessors without floating point hardware. It creates a significant overhead. The convenience of floating point computations should only be used when you can afford it, such as when experimenting in Matlab. But when you are looking for an efficient design that can run on an embedded processor, you have to reconsider how you compute with fractional numbers. Fixed-point data representation, which we will discuss next, is one such a strategy to obtain highly-efficient computations with fractional numbers.
Fixed-Point Data Representation
Fixed-point data types represent fractional data (such as 0.25), but they use integers and integer operations to achieve that goal. Compared to floating-point data types, integer data types are easier to handle on a microcontroller. First, integer-precision hardware uses less power than floating-point precision hardware at a similar operation troughput. Next, compared to emulated floating-point arithmetic, fixed-point arithmetic is (almost) as efficient as fast as integer arithmetic. Fixed-point data types are therefore a popular target for DSP implementations in constrained environments where power/performance is a concern.
We will discuss a method to convert the data types in a DSP program from floating-point data representation to fixed-point data representation. The conversion process from a DSP program using floating-point data types into a DSP program using fixed-point data types, is called fixed-point refinement.
Unsigned Fixed-point representation
Assume an unsigned integer datatype with bits 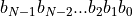 . The value of the unsigned integer number is defined as follows.
. The value of the unsigned integer number is defined as follows.
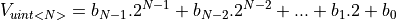
In a fixed-point representation, the binary point shifts from the right-most position to a different position  . Hence, a fixed-point representation is defined by the number of bits
. Hence, a fixed-point representation is defined by the number of bits 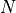 as well as the position of the binary point . For an unsigned number we adopt the notation
as well as the position of the binary point . For an unsigned number we adopt the notation ufix<N,k>, where ufix means ‘unsigned fixed-point’. An unsigned integer as defined above would be ufix<N,0>. The value of a fixed point number ufix<N,k> is computed as follows:
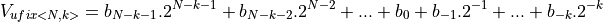
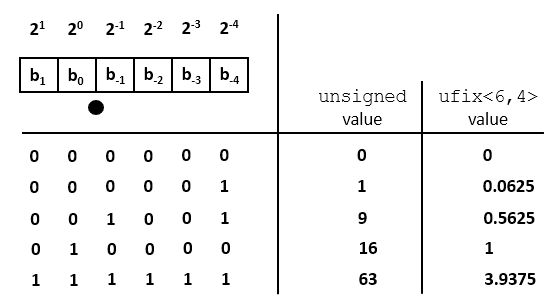
An ufix<N,k> fits in the same number of bits as an N-bit unsigned integer. The only difference lies in our interpretation of what these bits mean. The following is an example for a ufix<6,4>. A given bit pattern can be evaluated to the formulas above to compute the integer value as well as the fixed-point value.
The value of an unsigned integer of N bits, and the value of an unsigned fixed point number ufix<N,k> are related through the following expressions.
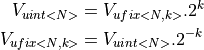
Signed Fixed-point representation
Signed values in integer arithmetic are captured in one of three different ways. The most common method is two’s complement, and we’ll focus on this method. The two other methods are one’s complement and sign-magnitude representation.
In a two’s complement representation, the value of a signed integer int<N> is defined as follows.
![V_{int<N>} = b_{N-1} . [-(2^{N-1})] + b_{N-2} . 2^{N-2} + ... + b_1 . 2 + b_0](_images/math/29e5e08a3684955bf137754dc8a6245b5cf3a7ea.png)
Thus, the weight of the most significant bit is negative. Similarly, the value of a signed fixed-point number fix<N,k> is defined as follows.
![V_{fix<N,k>} = b_{N-k-1} . [-(2^{N-k-1})] + b_{N-k-2} . 2^{N-2} + ... + b_0 + b_{-1} . 2^{-1} + ... + b_{k} . 2^{-k}](_images/math/9ce7de9dca8c59a9888a4eabb265012a61759c63.png)
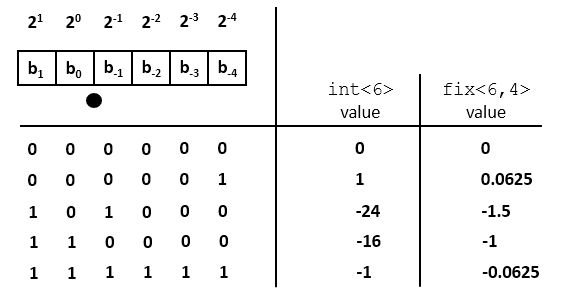
Thus the only difference between signed and unsigned representation is the weight of the most significant bit (positive for unsigned, negative for signed two’s complement.) The relationship between the value of the integer and fixed-point representation is the same as above:
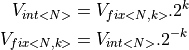
Conversion from Floating Point to Fixed Point
N-bit fixed-point numbers can be conveniently represented as N-bit integers, and in a C program we will use integer data types (int, unsigned) to store fixed-point numbers. A floating-point number is converted to a fixed-point number by proper scaling and conversion to an integer data type.
To convert a floating point number to a fixed point one, we first scale it up by 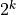 so that the least significant fractional bit gets unit weight. This conversion can lead to precision loss (at the LSB side) and overflow (at the MSB side). The following program illustrates the conversion to a
so that the least significant fractional bit gets unit weight. This conversion can lead to precision loss (at the LSB side) and overflow (at the MSB side). The following program illustrates the conversion to a fix<8,6> datatype.
#include <stdio.h>
void main() {
float taps[5] = {0.1, 1.2, -0.3, 3.4, -1.5};
int taps_8_6[5]; // a fix<8,6> type
unsigned i;
for (i=0; i<5; i++)
taps_8_6[i] = (int) (taps[i] * (1 << 6));
for (i=0; i<5; i++)
printf("%+4.2f %10d\n", taps[i], taps_8_6[i]);
}
The program generates the following output:
+0.10 6
+1.20 76
-0.30 -19
+3.40 217
-1.50 -96
The value of a fix<8,6> lies between -2 (for pattern 10000000) and 1.984375 (for pattern 01111111), which corresponds to integer values -128 to 127. Hence, the floating value +3.40 has suffered overflow during the conversion; its integer value is 217. The C program does not suffer from this overflow effect because we’re emulating the fix<8,6> in an int.
In addition, some of the floating point numbers (like 0.1) cannot be expressed exactly. Indeed, the value 6 maps to the bit pattern 00000110, or 0.09375. Hence, that conversion suffered precision loss.
Note that negative numbers are printed negative because of sign extension. For example, -19 corresponds to the bit pattern equals 1111…11101101. The lower 8 bits are 11101101, while the upper 24 bits are all 1, extending the sign bit of fix<8,6>.
Overflow is a highly non-linear effect with dramatic impact on the results of a DSP computation. It must be detected (and prevented).
Conversion from Fixed Point to Floating Point
After computations in fixed point precision are complete, we can convert the result back to a floating point representation, in order to obtain the numerical result. The conversion will scale down the integer value of a fixed-point number by a factor , so that the least significant bit gets its actual weight.
Special care has to be taken if the MSB of the fixed point representation is not located at the MSB of the integer representation. Indeed, to obtain the correct sign in the converted result, we have to replicate the MSB of the fixed point representation to get sign extension. The following program illustrates the conversion from a fix<8,6> datatype.
#include <stdio.h>
void main() {
int taps_8_6[5] = {6, 76, -19, 127, -96}; // a fix<8,6> type
float taps[5]; // a fix<8,6> type
unsigned i;
for (i=0; i<5; i++)
taps[i] = taps_8_6[i] * 1.0 / (1 << 6);
for (i=0; i<5; i++)
printf("%10d %+4.6f\n", taps_8_6[i], taps[i]);
}
The program generates the following output:
6 +0.093750
76 +1.187500
-19 -0.296875
127 +1.984375
-96 -1.500000
Note that the fixed-point conversion introduces quantization which prevents perfect reconstruction of the floating-point value. For example, float(0.1) can be converted to fix<8,6>(6), but the opposite conversion yields float(0.09375).
Fixed Point Arithmetic
Because fixed-point representation is strongly related to integer representation, we are able to express arithmetic operations on fixed-point numbers in terms of integer operations. Let’s first derive a few basic rules. We’ll make the derivation for unsigned numbers.
Addition
When we add two ufix<N,k> numbers, then the result is an ufix<N+1,k> number. The extra bit at the MSB side is there to capture the carry bit, in case one is generated. The subtraction of two ufix<N,k> numbers uses the same rule, since the subtraction can be defined as the addition of a ufix<N,k> with the two’s complement version of the other ufix<N,k>.
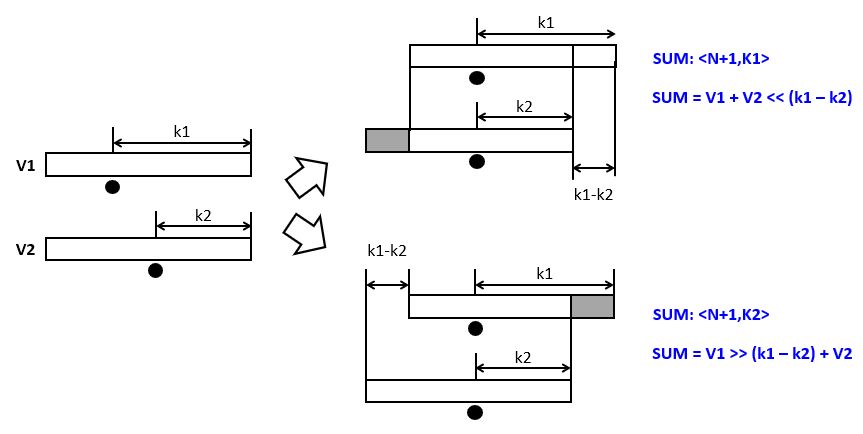
When we add a ufix<N,k1> number to a ufix<N,k2> number, with k1 > k2, then the two numbers have to be aligned first. This will increase the wordlength of the sum with k1 - k2 bits. However, if we desire to capture the sum as an N+1 bit number, then there are two possible alignments.
For a
ufix<N+1,k1>sum, we will have to increase the number ofufix<N,k2>fractional bits with a left-shift before addition.For a
ufix<N+1,k2>sum, we will have to decrease the number ofufix<N,k1>fractional bits with a right-shift before addition.
Since the total sum has only N+1 bits, there is potential precision loss, as illustrated in the following figure. Left-shifting V2 may cause an overflow when MSB-side bits are lost, while right-shifting V1 may cause precision loss when LSB-side bits are lost. The bottom line is that, when combining numbers with a different number of fractional bits, an alignment must be done which may cause either precision loss or else overflow.
Multiplication
When we multiply two ufix<N,k> numbers, then the result is a ufix<2N,2k> number. If the result has to be captured in an ufix<N,k>, then the result of the multiplication has to be right-shifted over k bits. In this case, overflow at the MSB side, and precision loss at the LSB side are both possible.
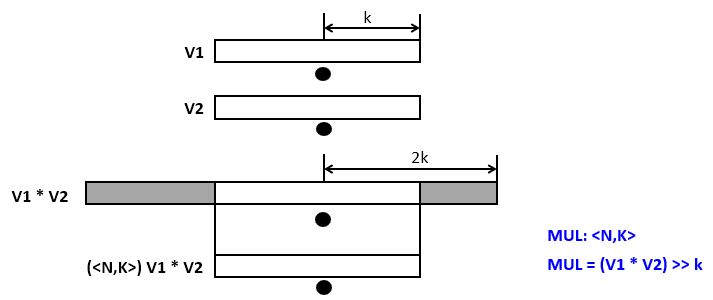
Example
The standard C operators use the following precision rules.
Adding two 32-bit integers will yield a 32-bit integer. Hence, overflow is possible.
Multiplying two 32-bit integers will yield a 32-bit product, which may cause overflow.
When we write a C program using integers to emulate fixed-point data types, the same precision rules will still apply. The following example illustrates how multiplication and addition in fixed-point representation works. We assume a vector with fix<8,7> coefficients which is multiplied with fix<8,7> tap values. We will implement these data types with a C int datatype.
#include <stdio.h>
void main() {
float c[5] = {0.2, -0.4, 0.8, -0.4, 0.2};
float taps[5] = {0.1, 0.2, 0.3, 0.4, 0.5};
float result;
int c_8_7[5];
int taps_8_7[5];
int result_16_14;
int i;
// convert c (float) to c_8_7 (fix<8,7>)
for (i=0; i<5; i++)
c_8_7[i] = (int) (c[i] * 128);
// convert taps (float) to tapsint (fix<8,7>)
for (i=0; i<5; i++)
taps_8_7[i] = (int) (taps[i] * 128);
// perform multiplication on a <32,14> data type
// <8,7> * <8,7> -> <16, 14>
result_16_14 = 0;
for (i=0; i<5; i++)
result_16_14 += (c_8_7[i] * taps_8_7[i]);
// perform multiplication on a float data type
result = 0.0f;
for (i=0; i<5; i++)
result += (c[i] * taps[i]);
printf("flp: %f fixp: %f\n", result, result_16_14 * 1.0f/(1<<14));
}
Since the result of the calculation is a <16,14> data type, we have to divide the result by 1 << 14 to find the equivalent real value. The output of the program is shown next.
flp: 0.120000 fixp: 0.115967
DSP with fixed-point arithmetic
When computing a digital filter using fixed-point arithmetic, systematic errors occur during the computation of a digital filter, called quantization noise. We’ll discuss the nature of quantization noise by means of an example using computations on a fix<3,2> datatype.
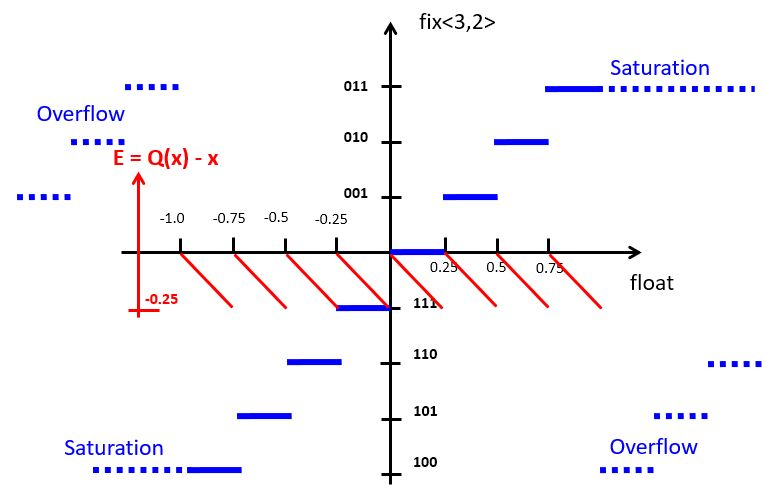
The blue staircase on the curve represents the conversion from floating point to fixed-point representation. For a fix<3,2>, the smallest quantization step is 0.25 so that the fixed point value increments for every 0.25 step. The highest positive output value, ‘011’, corresponds to floating point value 0.75. If we increase one more quantization step, overflow will occur. At the negative side, the staircase decreases a step for every 0.25 decrease.
An alternate of overflow is saturation, a technique that caps the most positive or most negative value that can be held in a fixed-point representation. This decreases the highly non-linear overflow effect in DSP. The implementation of saturating arithmetic, however, is more complicated than integer arithmetic. In our implementations, we will rely on plain integer arithmetic, which has overflow.
The red curve indicates the quantization error, the difference between the quantized value and the real (floating point) value. The quantization error for two’s complement fixed-point representation is always negative, which means that the value in the fixed-point representation always under-estimates the true value. The particular sawtooth shape of the error curve, however, demonstrates an important property of quantization noise: it is uniformly distributed over the range of one quantization step. In this case, the quantization error is uniformly distributed over the range [-0.25, 0].
Quantization noise will degrade signal quality. Assuming that the input signal can be treated as a uniformly distributed random variable (i.e., every value is equally likely), then quantization will behave like a uniformly distributed random variable too. Quantization noise therefore appears a as wideband noise in the signal output.
Fixed-point quantization on the MSP-432 kit
So far, we have converted the 14-bit ADC values into floating point values before starting the filtering, and from floating point values back into 14-bit DAC values after filtering.
uint16_t processSample(uint16_t x) {
float32_t input = adc14_to_f32(x);
// ... processing
return f32_to_dac14(input);
}
For fixed-point computations, we make use of one of two possible conversions to fixedpoint. adc14_to_q15() converts ADC samples into a fix<16,15> data type, while adc14_to_q31() converts ADC samples into a fix<32,31> data type.
The following figure shows the correspondence between analog values, DAC and ADC codes, floating point values, and fixed-point values.
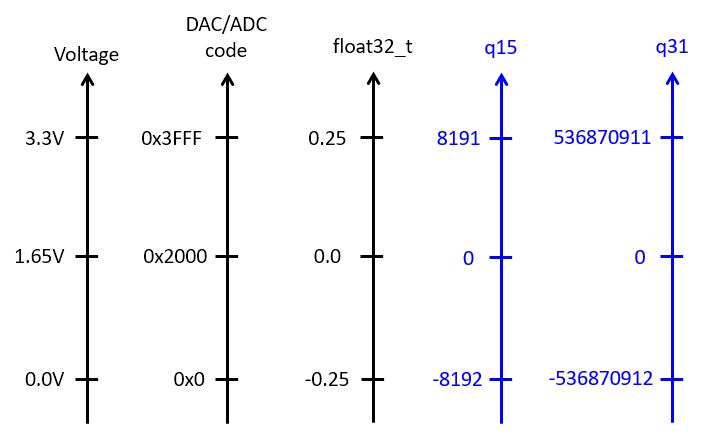
When writing fixed-point implementations of a filter, it’s crucial to remember the data type of the samples: fix<16,15> for a Q15, and fix<32,31> for a Q31. For example, if you multiply these samples with coefficients of type Q15 (fix<16,15>), then the result will be fix<32,30> for Q15 * Q15, and fix<48,46> for Q15 * Q31.
The former case, Q15 * Q15, requires downshifting before it can be send to the DAC output. The latter case, Q15 * Q31, will require a 64-bit integer, since 48 bits do not fit into a standard 32-bit integer.
Let’s look at the fixed-point implementation of the following first-order low-pass filter:
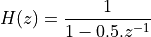
A floating-point version of this filter is straightforward to capture:
float32_t lpfloat(float32_t x) {
static float32_t state;
float32_t y = x + state * 0.5;
state = y;
return y;
}
To quantize this design, we adopt a Q15 data type for the input x. In addition, the state variable and the coefficient 0.5 are represented as Q15 values as well. The complete quantized filter is given by the following code:
q15_t lpq15(q15_t x) {
static int state; // accumulate as fix<16,15>
const int coeff = (int) (0.5 * (1 << 15)); // coeff as <16,15>
int mul = state * coeff; // mul is <32,30>
state = x + (mul >> 15); // add <16,15> and <17,15>
int y = state; // return output
return y;
}
Fixed-point quantization in Matlab Filter Designer
In Matlab, filter coefficients can be generated directly in fixed-point precision in filterDesigner. Often, a filter is first designed using floating-point precision in order to decide on the proper filter order and filter type. Next, the filter coefficients are quantized such that the floating point filter characteristic shows limited degradation. This entire process is highly automated by filterDesigner, as the following example shows.
Let’s build a FIR design with the following specifications: 8 KHz sample rate, lowpass characteristic, passband frequency 1 KHz, stopband frequency 2 KHz, passband response (ripple) 1dB, stopband response 80 dB. At first sight, this is a fairly straightforward filter, with the main challenge perhaps the 80 dB suppression characteristic in the stopband.
Filter designer creates a 19th order FIR with coefficients as follows.
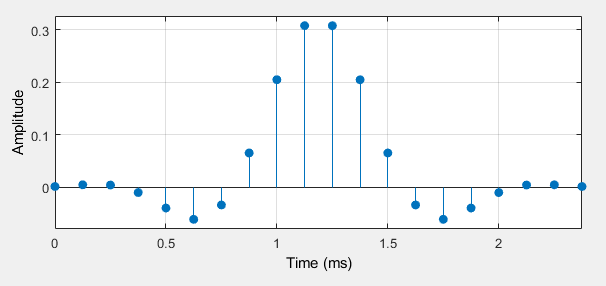
Because the stopband suppression is significant, many zeroes are needed throughout the stopband.
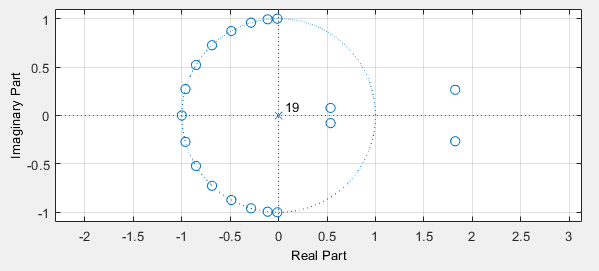
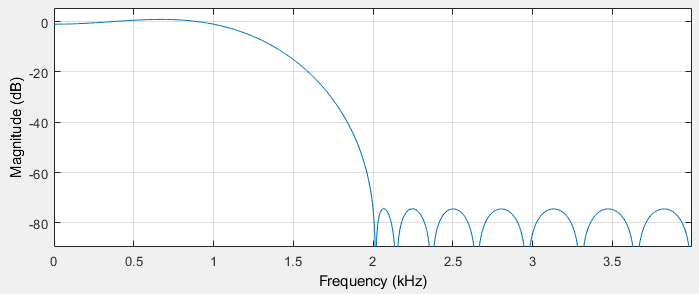
Next, we create a quantized version of the filter using the quantizer tool. This tool allows you to choose the wordlength of coefficients, and next attempts to derive a set of quantized coefficients that keep the filter characteristic as close as possible to the original.
In our example, we will give the fixed point tool a difficult job be allowing only 8-bit coefficients. Quantizing the coefficients will obviously impact the location of the zeroes of the filter, and as a result also the filter characteristic. The designer tool will show both the quantized filter characteristic as well as the floating point filter characteristic. A significant bump appears in the stopband, caused by zeroes moving to a non-ideal quantized grid location.
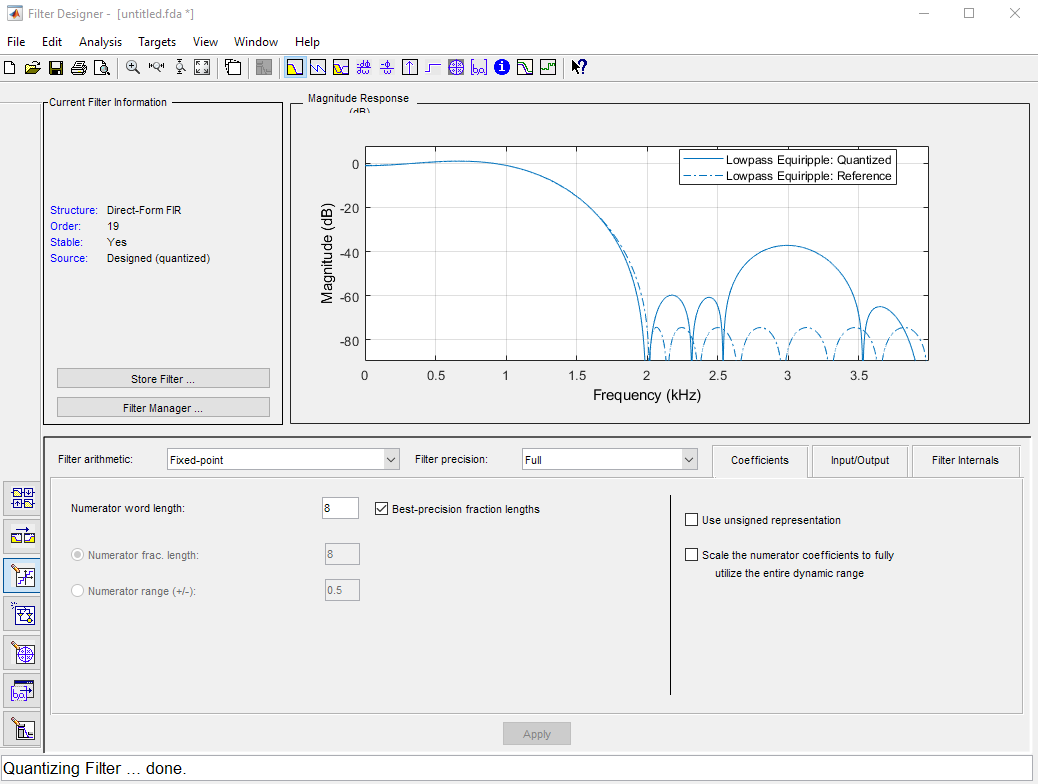
The resulting quantized filter has a quite different set of zeros.
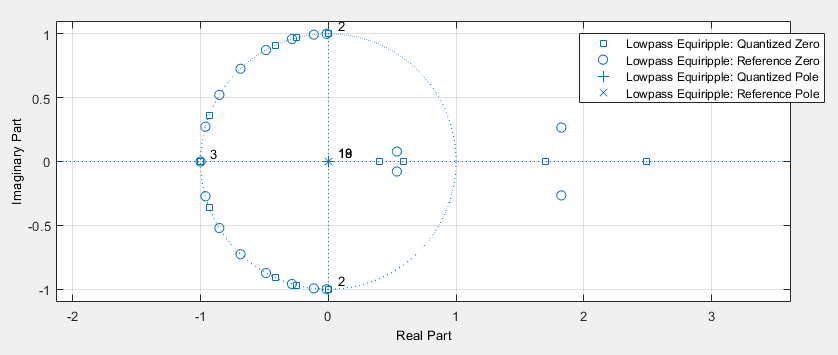
The filter coefficients of a quantized filter can be exported in the same manner as floating-point coefficients. The coefficients of the quantized filter are as follows.
Note the data type specification in the comment section of the output. s8,8 is a signed
fixed-point data type with 8 fractional bits and 8 bits overall. s25,23 is a signed
fixed-point data type with 23 fractional bits and 23 bits overall.
/*
* Discrete-Time FIR Filter (real)
* -------------------------------
* Filter Structure : Direct-Form FIR
* Filter Length : 20
* Stable : Yes
* Linear Phase : Yes (Type 2)
* Arithmetic : fixed
* Numerator : s8,8 -> [-5.000000e-01 5.000000e-01)
* Input : s16,15 -> [-1 1)
* Filter Internals : Full Precision
* Output : s25,23 -> [-2 2) (auto determined)
* Product : s23,23 -> [-5.000000e-01 5.000000e-01) (auto determined)
* Accumulator : s25,23 -> [-2 2) (auto determined)
* Round Mode : No rounding
* Overflow Mode : No overflow
*/
/* General type conversion for MATLAB generated C-code */
#include "tmwtypes.h"
/*
* Expected path to tmwtypes.h
* C:\Program Files\MATLAB\R2020a\extern\include\tmwtypes.h
*/
const int BL = 20;
const int32_T B[20] = {
0, 1, 1, -3, -10, -16,
-9, 17, 52, 79, 79, 52,
17, -9, -16, -10, -3, 1,
1, 0
};
How can we compute a filter with these coefficients? First, note that the input of this filter is a Q15 data type, which has 15 fractional bits. We design a direct-form FIR that processes this data type. Because the coefficients have 8 fractional bits, we must downshift each multiplication result by 8 positions after the multiplication with a fixed-point data type.
q15_t taps_fix[FIRLEN];
q15_t fir_fix(q15_t x) {
taps_fix[0] = x;
q15_t q = 0.0;
uint16_t i;
for (i = 0; i<FIRLEN; i++)
// <16,15> * <8,8> = <24,23>
// <24,23> >> 8 -> <16,15>
q += (taps_fix[i] * coef_fix[i]) >> 8;
for (i = FIRLEN-1; i>0; i--)
taps_fix[i] = taps_fix[i-1];
return q;
}
Tracking Quantization Noise from Matlab Filter Designer
Attention
The source code of this example is in the fixedpointlp project of the repository for this lecture.
Finally, let’s implement the 19-tap filter directly in floating-point as well as in fixed-point precision, and build a design that allows the visualization of each filter’s spectrum, as well as the quantization noise (the difference between floating point and fixed point output). The following processSample function illustrates this functionality. When the filter runs by itself, it will run in floating point precision (with native support). When the left button is pressed, the filter runs in fixed point precision using a Q15 input and 8-bit coefficients. When the right button is pressed, both filters run but we look only at the output. Note that we convert a Q15 data type to a float before taking their difference.
uint16_t processsample(uint16_t x) {
if (xlaudio_pushButtonLeftDown()) {
// LEFT BUTTON: fixed point version
return xlaudio_q15_to_dac14(fir_fix(xlaudio_adc14_to_q15(x)));
} else if (xlaudio_pushButtonRightDown()) {
// RIGHT BUTTON: difference between fixed & floating point version
float32_t qf = fir_float(xlaudio_adc14_to_f32(x));
q15_t qt = fir_fix(xlaudio_adc14_to_q15(x));
float32_t qt2float;
arm_q15_to_float(&qt, &qt2float, 1);
return xlaudio_f32_to_dac14(qf - qt2float);
} else {
// NO BUTTON: pfloating point version
return xlaudio_f32_to_dac14(fir_float(xlaudio_adc14_to_f32(x)));
}
}
The floating-point response stays close to our design. The stopband suppression is close to 70 dB, similar to the floating-point matlab characteristic.
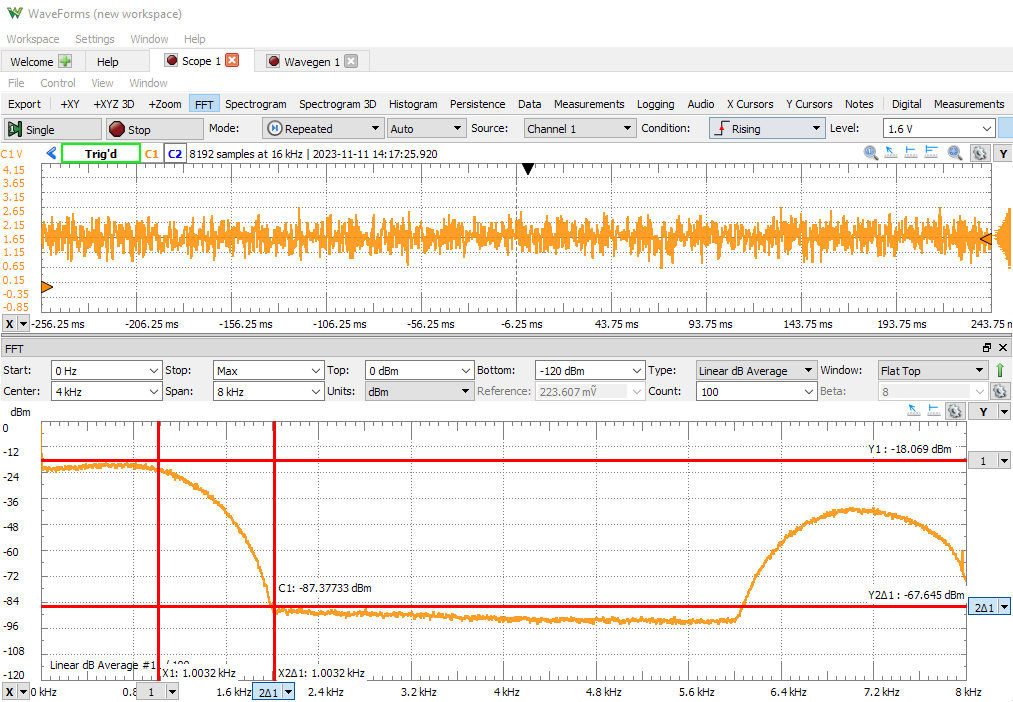
The spectrum of the quantized filter (left-button pressed) shows a significant distortion due to the use of 8-bit coefficients. Also, the stopband suppression is degraded by 10 dB.
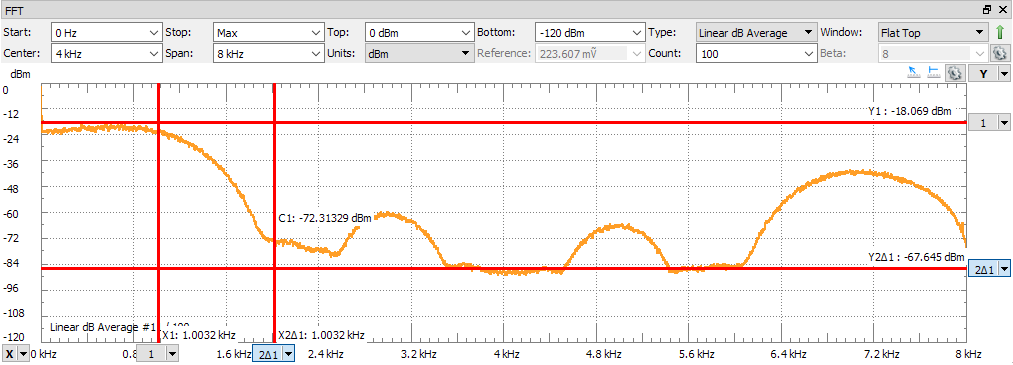
Measuring the quantization noise requires cranking up the sensitivity of the scope (from 500 mV/div to 10 mV/div). With that adjustment, the quantization noise becomes visible and. The spectral characteristic of the quantization noise is defined by the difference of the floating point response and the fixed point respone filter, and therefore isn’t uniform.
Conclusions
We introduced fixed-point data representation as a technique to implement DSP programs using integer arithmetic. In applications where floating point hardware is unavailable, fixed-point implementations are crucial.
We discussed the representation of a fixed-point data type, as well as the rules for addition and multiplication using fixed-point data types. Crucially, in fixed-point arithmetic the programmer is responsible for data alignment of the expression operands. That alignment, in addition to ensuring that sufficient wordlengths are available (so as to prevent overflow), is the key challenge in using fixed-point arithmetic.
We discussed the impact of fixed-point arithmetic on DSP, and in particular the additional quantization noise that gets generated because of fixed-point. Finally, we illustrated fixed-point arithmetic in a simple lowpass filter. A tool such as Matlab filterDesigner has built-in logic to quantize filter coefficients to a desired length, while analyzing the impact of quantization on the filter characteristic.